28. marts 2023
De seneste måneder har AI-teknologier som GPT-4 og Midjourney overtaget den digitale nyhedsstrøm. Kunstig intelligens ser ud til at være kommet for at blive, og med nye værktøjer kommer nye løfter om tidsbesparelse, øget produktivitet og økonomisk vækst. Men hvad kan teknologierne egentlig? Er de overhovedet klar til at indgå i data- og indholdsproduktion? Og bør vi overhovedet bruge dem?
Der er ingen tvivl om, at moderne kunstig intelligens virker til at være meget tæt på, at være et reelt alternativ til menneskelig kreativitet. Eller det indtryk kunne man i hvert fald godt få, hvis man læste mange af de opslag om AI (kunstig intelligens), der ser dagens lys i disse måneder.
Spørgsmålet er så, om dette er tilfældet, og om det i så fald skyldes, at vi alle sammen er blevet mindre kreative i vores jagt på evig procesoptimering? Eller om teknologierne simpelthen bare er blevet så modne, at vores menneskelige kognition ikke længere kan følge med?
Svaret ligger nok et sted imellem de to yderligheder.
Fælles for de populære AI-teknologier, der i disse dage ser dagens lys, er, at de falder i kategorien "Generative kunstige intelligenser". Det output de præsenterer os for, at altså ikke kreativt i gængs forstand, men er i stedet "gætværk", hvormed den kunstige intelligens på baggrund af millioner af tekster den har læst, forsøger at gætte sig til, hvordan en ny tekst kunne se ud. GPT'et i ChatGPT står således også for "Generative pre-trained transformer".
Alle de outputs vi får fra generative AI'er som fx ChatGPT, er altså et forsøg på at tilfredsstille det input (fx et spørgsmål), vi som brugere stiller den kunstige intelligens. Der er ingen fri vilje, der ingen skjulte mål - udelukkende et forsøg på at gætte hvad det næste ord i sætning kunne/bør være, for at teksten AI'en udskriver, er læsbar og anvendelig.
Alt efter hvilken opgave vi forsøger at løse, kan et mindre unikt/originalt output (fx fra en AI) være fyldestgørende.
Det kunne fx være en produkttekst på et par hvide tennissokker, hvor kravene til god copywriting ikke for alvor er til stede, men hvor et læsbart output på 150 tegn er målsætningen.
Og netop her viser kunstig intelligens sig at være klar til tjeneste.
Men skal vi bare bruge kunstig intelligens fuldstændig ukritisk? Og I hvilke situationer kan den kunstige intelligens overhovedet levere et output, der kan indgå direkte i "produktion"?
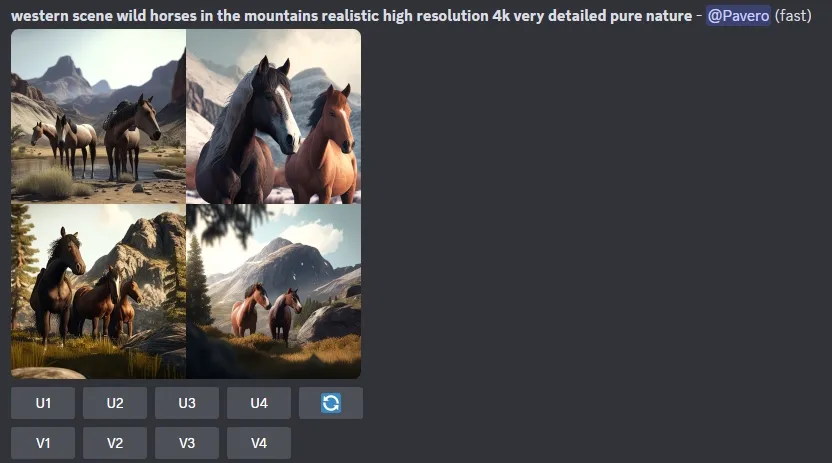
Midjourney er en af de generative kunstige intelligens-teknologier, der nyder størst opmærksomhed i disse dage. Via chatklienten "Discord" (herover) kan brugere indtaste forespørgsler på AI-generet kunst, ved fx at skrive "/imagine western scene wild horses in the mountains realistic high resolution 4k very detailed pure nature", hvorefter brugeren præsenteres for 4 eksempler på det ønskede motiv (se eksemplet herover).
Kunstig intelligens - hvor er faldgruberne?
Selvom nettet koger over med gode eksempler på AI-generet indhold (fx i en PIM-løsning) og AI-understøttede processer, er det altid sundt at gå til ny teknologi med en vis portion skepsis. Særligt når den nye teknologi kræver adgang til vores produktionsmiljøer og data.
Faldgruber ved AI set i et etisk perspektiv
I forhold til det etiske perspektiv af brugen af kunstig intelligens ser vi hver dag flere og flere eksperter udtrykke deres bekymring for den teknologiske udvikling.
Nogle af de mest fremtrædende dilemmaer omkring etik og kunstig intelligens lader for tiden til at være:
- Er en kunstig intelligens et "væsen", der fortjener rettigheder, ligesom vi mennesker gør?
- Hvordan er en kunstig intelligens som GPT-4 blevet trænet, og er det en praksis, virksomheder bør understøtte?
- Hvordan forholder vi os til, at en kunstig intelligens potentielt kan erstatte menneskelig arbejdskraft i fremtiden?
- Senest har en gruppe eksperter fra både ind- og udland udvist bekymring i forhold til den manglende regulering af området.
Kort fortalt har PicoPublish som virksomhed ikke etableret nogen fast politik, når det kommer til de etiske overvejelser, der følger med brugen af en AI.
AI - et nyt paradigme, der endnu ikke er tøjlet
Vores overbevisning er, at AI repræsenterer et nyt teknologisk paradigme, og at der både er klare produktionsmæssige fordele at drage af anvendelsen af AI, men at vi samtidigt slet ikke tør spå om de juridiske, politiske og samfundsmæssige implikationer, dette paradigme medfører.
Når vi snakker om generative kunstige intelligenser som fx Midjourney, der genererer billeder på baggrund af brugerens input, er der nogle etiske overvejelser i spil, hvor vi som rådgiver på nuværende tidspunkt udelukkende kan rådgive ud fra et teknisk snarere end et etisk perspektiv.
Spørgsmål som "Bør vi bruge sådan en teknologi?" bliver relevante, når kunstnere i hobetal fremhæver, at den pågældende teknologi udelukkende kan fungere, fordi AI-modellen er trænet på data (billeder/kunstværker), der har været frit til rådighed på nettet.
Hvem tjener pengene på AI?
Argumentet er bl.a., at Midjourney står til at tjene stort på deres subscription-model, alt imens de kunstnere der ufrivilligt har leveret træningsmateriale til denne AI, ikke får en krone.
Uanset hvad bør vi som virksomheder overveje, hvordan vi begår os digitalt, og om vi skærer den gren, som vi sidder på over, når vi kaster os over brugen af kunstig intelligens.
For nu følger vi udviklingen tæt, og tager løbende stilling til de tekniske, juridiske og samfundsmæssige konsekvenser vores rådgivning har.
Faldgruber ved AI set fra et teknisk perspektiv
Når vi bevæger os over i en lidt mere teknisk fokuseret arena, og glemmer livets store spørgsmål om mening, agens og samfund, er der en række mere konkrete spørgsmål, der melder sig på banen:
- Hvem ejer de data, der bliver fodret til en AI som fx GPT-4?
- Er GPT-4-output faktuelt korrekt, og kan vi overhovedet bruge det i produktionsmiljøer?
- Kan brugen af AI-genereret indhold skade vores digitale omdømme?
- Hvor sikker er teknologien?
Viser det sig, at de data du fodrer en en kunstig intelligens som GPT-4 med, bliver sendt ud af landet og ind i en stor database, kan det være et problem i forhold til compliance.
Lad os kort prøve at kigge på spørgsmålene herover, og undersøge, hvad vi på nuværende tidspunkt kan sige om disse.

Det er for nuværende svært at sige præcist hvordan de data, som vi fodrer de kunstige intelligenser med, bliver brugt. I USA har en domstol stadfæstet, at man ikke kan håndhæve en copyright på et AI-genereret billede.
Skal vi snakke data?
Hvis du har lyst til at høre vores bud på, hvordan data kan hjælpe jeres forretning med at eksekvere, vækste og skalere, står vi klar til en uforpligtende snak.
1. "Hvem ejer data"?
Det korte svar: Det ved vi ikke præcist. I de fleste tilfælde må du dog bruge outputtet kommercielt, uden at bryde nogle ophavsrettigheder. Vær opmærksom på, at de tjenester du benytter, også må gemme og bruge det indhold, du giver dem. Du har dog heller ikke copyright på materiale genereret via fx Midjourney!
Hvad sker der med de data (tekst/billeder), du fodrer en kunstig intelligens med?
For ChatGPT kan vi lige så godt starte med at sige, at de (altså OpenAI) i princippet kan vælge at beholde alle de data, du giver den.
I OpenAI's privatlivspolitik skriver de følgende:
"User Content: When you use our Services, we may collect Personal Information that is included in the input, file uploads, or feedback that you provide to our Services (“Content”)." - Kilde, OpenAi.com
Giver du ChatGPT adgang til 100.000 af dine produkter, og beder du den om at skrive dine produkttekster for dig, risikerer du altså, at disse data bliver brugt til at træne den sprogmodel, din konkurrent også bruger.
Her må I som forretning afgøre, om den rå computerkraft AI'en stiller til rådighed, er mere værd, end den potentielle gevinst I sender videre til jeres konkurrenter.
For Midjourney gælder det bl.a., at de amerikanske domstole har afgjort, at man ikke kan have copyright på billeder, der er genereret af en kunstig intelligens.
Ejerskab, rettigheder og en række andre juridiske spørgsmål afventer fortsat, at lovgivningen bliver prøvet. Indtil da er der en række tekniske forhold - fx OpenAI's ret til at anvende din data til research - der bør være i jeres overvejelser, når I bruger GPT-4-modellen eller tilsvarende.
For nu gør du klogt i at antage, at de data der bliver genereret med AI-værktøjerne, IKKE er under nogen form for copyright-beskyttelse.

De nye kunstige intelligenser kan dybest set ikke stille nogle garantier for, at deres output er faktuelt korrekt. Derfor skal man bruge disse værktøjer med stor forsigtighed, hvis man lader disse indgå i et produktionsmiljø (fx indholdsproduktion til en webshop).
2. Kan vi stole på det output GPT-4 genererer?
Det korte svar: Nej, faktuelt er der fortsat faldgruber i det output, kunstig intelligens genererer.
Der er flere forhold omkring den måde, som GPT-4 er trænet, og fungerer på, der giver anledning til at tænke sig grundigt om, inden man slipper den løs i produktionsmiljøer.
For det første er ChatGPT og GPT-4-modellen generative. Det vil sige, at den "finder på" ting, baseret på de erfaringer den har gjort sig med det materiale, den er blevet trænet på. Det betyder også, at en model som GPT-4 ikke kan stilling til aktuelle begivenheder, da den ikke kender detaljerne omkring nylige hændelser.
"Hallucination" i kunstig intelligens
Det betyder bl.a. at ChatGPT kan "hallucinere", og altså sammensætte overbevisende argumenter, der ikke er faktuelt korrekte - fx ved at oplyse forkerte kilder. Et eksempel fra den kunstige intelligens, der lige nu er offentliggjort på søgemaskinen Bing, viser, at kunstig intelligens fx kan overbevise sig selv om, at den har ret, selvom den (altså Bing) tydeligvis tager fejl:

Kilde: Simonwillison.net (Februar, 2023)
Begrebet "hallucination" dækker hos en kunstig intelligens over det faktum, at sprogmodellen som en AI bygger på, dybest set ikke forstår sproget, og derfor ikke kan forholde sig til, om det den skriver er sandt eller falsk:
“Those systems [ChatGPT] generate text that sounds fine, grammatically, semantically, but they don’t really have some sort of objective other than just satisfying statistical consistency with the prompt.” - Yann LeCun, Deep Learning Pioneer
GPT-4 er et neuralt netværk, der har opnået sine "kompetencer", ved at kigge på en hel masse forskellige tekster og billeder - bl.a. fra projektet CommonCrawl, der stiller en masse åbne webdata til rådighed (se mere på Wikipedia her).
Helt konkret har offentligheden ikke fuld indsigt i hvordan fx GPT-4-modellen er blevet trænet, men vi ved, at GPT-3.5 var trænet på datasæt, der kun indeholdt data der var indsamlet til og med 2021. Af forretningsmæssige hensyn er meget af GPT-4-modellens arkitektur ikke offentligt tilgængeligt. Desværre kan vi derfor ikke sige meget om det datagrundlag, som GPT-4-modellen bygger på.
De fleste AI'er har et bias - husk det, når du bruger deres output
Vi kan dog konkludere, at GPT-modellerne har et bias. Vi kan ikke sige præcist hvad dette bias er, ligesom vi heller ikke kan konkludere, at det er en skidt ting, at GPT-modellerne har dette bias - for det har vi som mennesker også alle sammen.
Det vi dog kan sige, er, at modeller skal bruges med omtanke, og nok ikke i henseender der er forretningskritiske (fx kan det være farligt at give en kunstig intelligens mandat i forhold til større strategiske beslutninger).
De generative AI-teknologier er kun så gode, som de inputs vi giver dem, og derfor kræver korrekt brug af teknologien også, at man lærer at forstå de muligheder og begrænsninger, dårlige brugerinputs medfører for kvaliteten af outputtet.

Forkert brug af AI-teknologier kan potentiel skade jeres digitale omdømme. Særligt hvis I ikke fører nogen kvalitetskontrol, med de resultater I præsenteres for. Søgemaskineudbydere som Google har endnu ikke en klar politik på området.
3. Kan brugen af AI-genereret indhold skade vores digitale omdømme?
Det korte svar: Måske. Der er en risiko for, at brugen af AI-genereret indhold kan spores, og dermed føre til en "straf" i forhold til indeksering/rangering på søgemaskiner som fx Google. Der er dog ingen officiel udmelding omkring dette fra fx Google, der generelt holder deres algoritmer meget tæt på kroppen.
Kan vi bruge tekster genereret af en kunstig intelligens, uden at fx Google straffer os (fx i forhold til SEO)?
Igen er svaret ikke helt tydeligt. Google, der fortsat er den største søgemaskine, har altid haft det standpunkt, at de ønsker at nedbringe mængden af "spammy content". Definitionen af "spammy content" er dog ikke helt tydelig.
I deres developer-guidelines skriver de følgende:
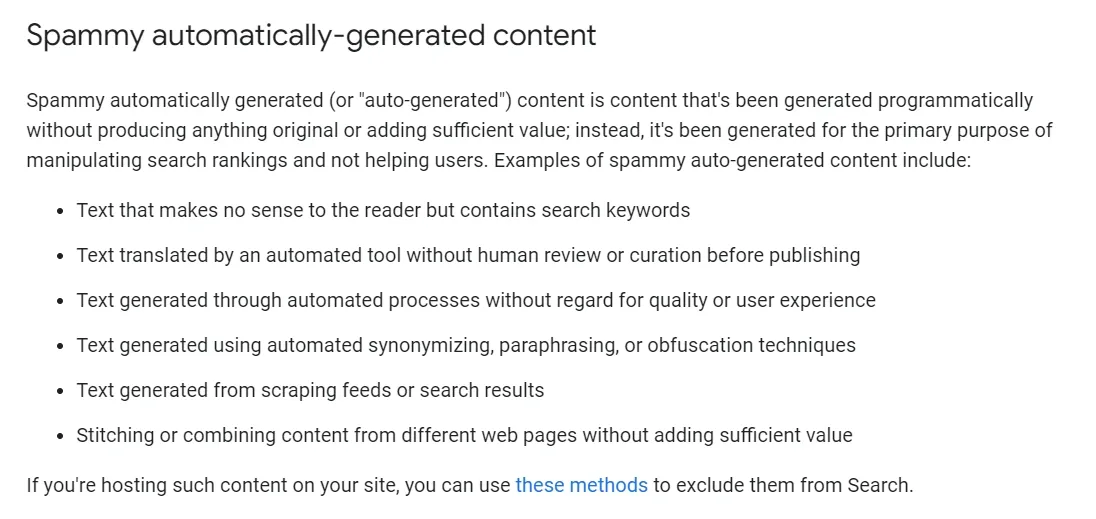
Kilde: Google Search Central (2023)
Med en teknologi som ChatGPT ved fingerspidserne, kan man dog argumentere for, at mange tekstforfattere og marketingmedarbejdere i dag er i stand til at producere endnu bedre artikler, hvilket kommer slutbrugeren til gode - så hvordan skal Google forholde sig her?
Igen må vi se, hvad den næste tid bringer. Teknologier som GLTR, der prøver at gennemskue hvorvidt en tekst er AI-genereret eller ej, kunne meget vel komme i spil, når Google og andre aktører forsøger at gennemskue, om en tekst er skrevet af en AI eller ej.
Hos virksomheden SEO.ai har man specialiseret sig i brugen af AI til søgemaskineoptimering. I deres seneste bud på hvordan man effektivt benytter en kunstig intelligens (fx ChatGPT) til at styrke ens SEO, er fremgangsmåden at bruge ChatGPT som sparringspartner, snarere end som en selvstændig tekstforfatter.

Efter alt at dømme er den seneste generation af AI-teknologier som ChatGPT og Midjourney ikke mindre sikre, end andre SaaS-produkter. Der følger dog en stor mængde teknologien i halen på de nye kunstige intelligenser, der kan være udviklet af ondsindede aktører.
4. Hvor sikker er teknologien?
Det korte svar: Sikker nok til, at vi tør bruge den uden forbehold. Men hele tech-miljøet koger lige nu over med "smarte teknologier", der potentielt er af skadelig karakter - så pas på derude.
Der er intet, der tyder på, sikkerheden omkring brugen af selve ChatGPT eller Midjourney skulle være mere usikker end hos andre lignende udbydere af SaaS-produkter.
Et enkelt "breach" på OpenAi
Der er i marts således kun et enkelt tilfælde at finde, når vi kigger efter deciderede "breaches" hos fx OpenAI. I dette tilfælde blev data/prompts delt med andre brugere, således at et input fra USER A kunne blive vist for USER B ved et uheld.
De fleste sikkerhedsudfordringer har karakter af at være phishing-forsøg, malware og andet ondsindede typer af angreb og teknologier, der omgiver brugen af de populære AI-tjenester.
Pas på nye phishing-metoder og malware
Med en stigende interesse for at anvende kunstig intelligens i hverdagen, leder mange folk i disse dage efter nye AI-værktøjer, der kan gøre livet lettere. Typisk kræver dette, at man installerer et plugin eller afgiver nogle oplysninger eller noget adgang til filer og mapper på ens devices, hvilket efterlader os sårbare som brugere.
Den gode tommelfingerregel for nu er derfor, at man er kritisk med hvilke data, man giver AI-teknologier adgang til, da vi dybest set ikke er sikre på, hvordan data bliver efterbehandlet/opbevaret.
Gå til nye AI-teknologier med stor forsigtighed
Ligeledes bør man gå til nye AI-teknologier med ekstrem forsigtighed, da der med garanti er mange "hackere" derude, der vil forsøge at udnytte den store interesse for AI-teknologier.
Dette gør sig også gældende for de mange Nigerianske prinser, der med garanti får et større ordforråd og bedre adgang til kontekstuel viden om os i de kommende måneder.
Hvad gør vi så nu?
Fra vores side af bordet vil den næste tid gå med at trykprøve de AI-løsninger, der melder sig på banen i vores egen arena.
Det gælder for eksempel Perfions nye AI-satsning, der tilbyder en AI-assistent direkte i Perfions grid.
De større politiske, juridiske og samfundsmæssige implikationer der følger med brugen af AI, må vi - ligesom alle andre - vente på.
Der er uden tvivl nogle gode, produktivitetsfremmende anvendelser af kunstig intelligens, der uden større risici kan tages i brug i produktionsmiljøer rundt omkring hos vores kunder.